How to Master Large Language Models (LLMs): A Step-by-Step Guide
Unlock the potential of Large Language Models (LLMs) with this comprehensive guide. Learn their fundamentals, architectures, training processes, and deployment techniques in 7 actionable steps to create impactful AI applications.


Nikhil Allamsetti
2024-12-10
Large Language Models (LLMs) have unlocked a new era in natural language processing. These models are trained on massive amounts of text data and can comprehend complex concepts, translate languages and produce creative text formats. Their growing importance is evident in a wide spectrum of industries. In this article, we will go from learning what large language models are to building and deploying LLM apps in 7 easy steps.
Step 1: Understanding LLM Basics
To effectively utilize large language models (LLMs), it is essential to grasp the fundamental concepts that underpin their remarkable capabilities. LLMs are a type of artificial intelligence (AI) system that can process and generate human-like text, enabling them to perform a wide range of natural language processing (NLP) tasks. Their ability to comprehend complex concepts, translate languages and produce creative text formats stems from their deep understanding of the patterns and regularities inherent in human language.
The foundation of LLMs lies in the field of NLP, which encompasses the interaction between computers and human language. NLP techniques enable machines to extract meaning from text, translate languages and generate human-like text. LLMs leverage these techniques to process vast amounts of text data, allowing them to learn the underlying patterns and regularities of language.
Step 2: Exploring LLM Architectures
The architecture of a large language model (LLM) plays a crucial role in determining its capabilities and performance. Different architectures employ distinct approaches to processing and generating text, each with its strengths and limitations. Here are the 3 main architectures of large language models (LLMs): Transformer, Recurrent Neural Network (RNN) and Convolutional Neural Network (CNN).
Transformer Architecture
The Transformer architecture is the most widely used in LLMs. It is a neural network architecture that uses self-attention mechanisms to process sequential input data. The Transformer architecture enables LLMs to capture long-range dependencies in text, enabling better contextual understanding.
Recurrent Neural Network (RNN) Architecture
The RNN architecture is another popular architecture used in LLMs. RNNs are neural networks that are designed to process sequential data. They are capable of handling variable-length input sequences and can capture temporal dependencies in data.
Convolutional Neural Network (CNN) Architecture
While CNNs are primarily associated with computer vision applications, their versatility extends to the realm of large language models (LLMs). CNNs excel at processing data arranged in a grid-like structure, a characteristic common to images. They are capable of capturing local dependencies in data and can be used to extract features from input data.
Step 3: Pre-training LLMs
Pre-training is the foundational step in developing large language models (LLMs). This process allows the LLM to learn the underlying structure and patterns of human language, laying the groundwork for its ability to perform various natural language processing (NLP) tasks. In this stage, the LLM is exposed to a vast amount of text data, such as books, articles and websites. The model is tasked with predicting the next word or phrase in a sequence, given the preceding words. This process allows the LLM to learn the statistical regularities of language, such as word order, grammatical rules and semantic relationships.
Step 4: Fine-Tuning LLMs
After the initial step of pre-training, large language models (LLMs) undergo fine-tuning, a process of tailoring the model to perform specific tasks or adapt to specific datasets. While pre-training provides the LLM with a broad understanding of language, fine-tuning refines this knowledge to address the nuances and requirements of a particular task.
Fine-tuning typically involves supervised learning, where the LLM is trained on a smaller, task-specific dataset of labelled data. These labels provide explicit examples of the desired output, allowing the model to adjust its parameters and learn the mapping between input text and the corresponding output. For instance, if the LLM is fine-tuned for sentiment analysis, it is provided with examples of text classified as positive, negative, or neutral. This process allows the model to learn the subtle cues and patterns that distinguish positive from negative sentiment.
Several techniques have been developed to enhance the efficiency and effectiveness of fine-tuning. One such technique is LoRA (Low-Rank Adaptation), which introduces a low-rank matrix as an adaptation layer to the pre-trained model. Another efficient fine-tuning method is QLoRA (Quantized LoRA), which quantizes the low-rank matrix in LoRA to further reduce computational requirements and memory usage.
Step 5: Alignment and Post-Training in LLMs
As large language models (LLMs) continue to evolve and their applications expand, it becomes increasingly crucial to ensure that their outputs align with ethical guidelines and user intentions. Alignment refers to the process of ensuring that the LLM's behaviour and outputs are consistent with human values, expectations and societal norms.
Post-training adjustments play a vital role in enhancing the model's alignment and performance. One such technique involves optimizing training parameters, such as learning rate, batch size and the number of training epochs, to refine the fine-tuning process and prevent overfitting.
Step 6: Evaluation and Continuous Learning in LLMs
Evaluating LLMs is crucial to ensure that they are performing optimally. LLMs can be evaluated for accuracy, coherence and relevance. Accuracy refers to how well the LLM performs on a specific task. Coherence refers to how well the LLM generates text that is contextually relevant and grammatically correct. Relevance refers to how well the LLM generates text that is relevant to the user’s query.
Continuous learning is important for LLMs to adapt to new data and trends. LLMs can be updated with new data to improve their performance over time. Continuous learning can be done using techniques such as online learning, where the model is updated in real-time as new data becomes available. Another technique is transfer learning, where the model is trained on a related task before being fine-tuned on the target task.
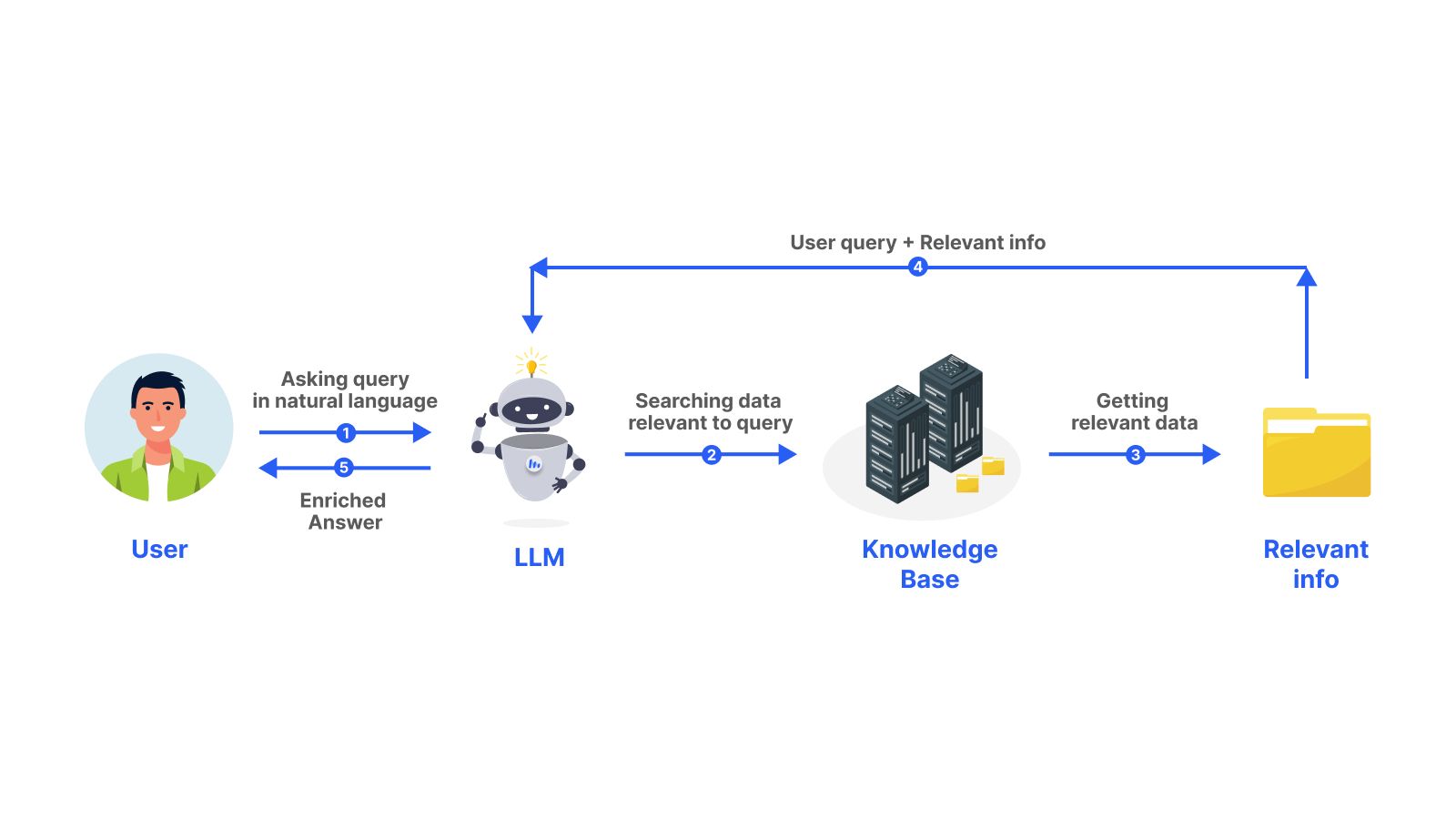
Step 7: Building and Deploying LLM Apps
Building and deploying LLM apps is the final step in LLM development. Building LLM apps involves integrating the LLM into an application. Deploying LLM apps involves making the application available to users. Building and deploying LLM apps requires specialized software development skills.
Selecting the right model and platform is crucial for building and deploying LLM apps. The choice of model depends on the specific task that the LLM app is designed to perform. Scaling and maintaining the application is also important for LLM app development. LLM apps can be scaled horizontally or vertically. Horizontal scaling involves adding more servers to the application to handle increased traffic. Vertical scaling involves adding more resources to the existing servers to handle increased traffic. Maintaining the application involves monitoring the performance of the LLM app and making necessary adjustments to improve its performance.
In conclusion, mastering LLMs requires a deep understanding of their principles, architectures and training methodologies. By following the steps outlined in this blog, individuals can gain the expertise necessary to harness the power of LLMs and develop innovative applications that transform industries and enhance human capabilities.
Related posts


Looking for a marketing purpose analytics tool?
Click HereNewsletter
Website owned by : KAIROS LABS PRIVATE LIMITED, Tonk Phatak Jaipur - 302015, Rajasthan
All Rights Reserved
Email : Support@llmate.ai